這部份原先是想在jsdc分享的展示,不過當時時間不夠,結果就沒有做這部份的展示。
node.js的模組功能有幾個必須了解的限制:
第二個限制,會讓deploy變得困難,每次都要重新啟動整個程式,不過利用cluster模組,搭配fs.watch的功能,就可以讓每次程式有變動就自動重新載入worker,來克服這個問題。
當然,如果程式寫壞,上線就自動死掉
簡單的邏輯,就是在master偵測程式變動,有變動時就重啟worker,這樣就不需要停止程式然後再啟動程式。
用一個簡單的hello world範例來看:
var cluster = require('cluster');
var http = require('http');
var numCPUs = require('os').cpus().length;
var fs = require('fs');
if (cluster.isMaster) {
// Fork workers.
var pool = {};
for (var i = 0; i < numCPUs; i++) {
createworker(pool);
}
cluster.on('death', function(worker) {
console.log('worker ' + worker.pid + ' died');
createworker(pool);
});
fs.watch('./test005.js', function() {
for(var i in pool) {
pool[i].send({cmd: 'suicide'});
}
});
function createworker(pool) {
var worker = cluster.fork();
var sid = new Date().getTime() + '' + Math.random();
worker.on('message', function(msg) {
if(msg.id) {
pool[msg.id] = null;
delete pool[msg.id];
}
});
pool[sid] = worker;
worker.send({id: sid});
console.log('worker created: ' + sid);
}
} else {
// Worker processes have a http server.
http.Server(function(req, res) {
res.writeHead(200);
res.end("hello world\n");
}).listen(8000);
var id = "";
process.on('message', function(msg) {
if(msg.id) {
id = msg.id;
}
if(msg.cmd && msg.cmd === 'suicide') {
process.send({id: id});
process.exit();
}
});
}
他做的事情很簡單,就是用fs.watch來監控檔案,有變動時,就叫worker自殺,然後master會自動重啟掛掉的worker。
先把程式跑起來:

從瀏覽器可以看到:

然後修改一下程式,把hello world改成hello world reload,存檔後就會看到伺服器有反應:
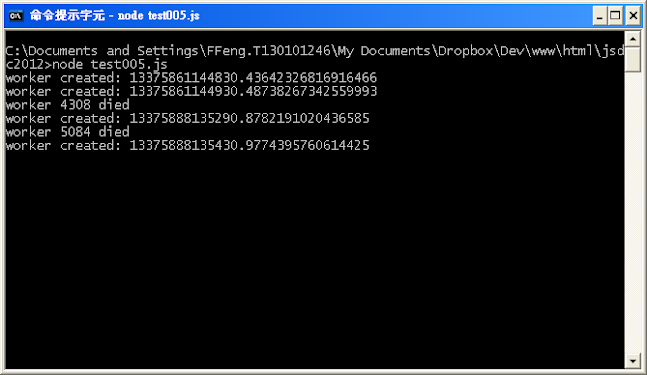
瀏覽器refresh一下,就會看到hello world變成hello world reload:

其實程式裡面,伺服器只有幾行,其他都是cluster相關的東西。對於只想專注於伺服器程式開發,其實可以把程式拆成兩個部分,配合一些「策略」定義,就可以把伺服器程式放進模組。例如:
這樣,伺服器的程式調整成
var cluster = require('cluster');
var numCPUs = require('os').cpus().length;
var fs = require('fs');
if (cluster.isMaster) {
// Fork workers.
var pool = {};
for (var i = 0; i < numCPUs; i++) {
createworker(pool);
}
cluster.on('death', function(worker) {
console.log('worker ' + worker.pid + ' died');
createworker(pool);
});
fs.watch('./main', function() {
for(var i in pool) {
pool[i].send({cmd: 'suicide'});
}
});
function createworker(pool) {
var worker = cluster.fork();
var sid = new Date().getTime() + '' + Math.random();
worker.on('message', function(msg) {
if(msg.id) {
pool[msg.id] = null;
delete pool[msg.id];
}
});
pool[sid] = worker;
worker.send({id: sid});
console.log('worker created: ' + sid);
}
} else {
// Worker processes have a http server.
var main = require('./main');
main.start();
var id = "";
process.on('message', function(msg) {
if(msg.id) {
id = msg.id;
}
if(msg.cmd && msg.cmd === 'suicide') {
main.stop();
process.send({id: id});
process.exit();
}
});
}
在程式目錄中,新增一個main目錄,然後把伺服器模組的index.js放進去,程式如下:
var http = require('http');
module.exports = {
start: function() {
http.Server(function(req, res) {
res.writeHead(200);
res.end("hello world reload\n");
}).listen(8000);
},
stop: function(){}
};
當然,做成模組比較好的方式是用package.json來描述,不過這裡只是做概念驗證,所以就用index.js來代替,這樣速度會比較慢就是了。
改過之後重啟伺服器,然後去修改模組中的index.js,可以看到有改並的話都會重啟worker,然後從瀏覽器就可以看到改變的結果。
接下來,大部分的時候,就只要去維護main裡面的東西,而且每次deploy,伺服器就會重啟worker,自動apply變更。這樣就很像做了一個簡單的hosting服務,只要依照上述的規則來寫模組,就可以在不知道hosting程式長怎樣的狀況下,專注於寫main模組中的程式。。
補充一下。
其實用fs.watch目錄的方式來實作,會有一個問題:每個檔案更新時,worker都會重啟一次,如果在做批次更新,一次更新很多檔案,就會造成worker不斷重啟,這樣會影響服務及效率。
也許可以從deploy工具下手,例如會在main目錄中自動新增一個timestamp檔,而程式就調整為fs.watch這個檔案。然後每次deploy完畢時,會去touch main/timestamp。這樣就可以讓每次deploy新的版本時,worker只會重啟一次。
 fillano
fillano

 iThome鐵人賽
iThome鐵人賽